DiTFastAttn: Attention Compression for Diffusion Transformer Models
Diffusion Transformers (DiT) have emerged as a powerful tool for image and video generation tasks. However, their quadratic computational complexity due to the self-attention mechanism poses a significant challenge, particularly for high-resolution and long video tasks. This paper mitigate the computational bottleneck in DiT models by introducing a novel post-training model compression method. We identify three key redundancies in the attention computation during DiT inference and we propose three techniques.
- Window Attention with Residual Caching - Reduces spatial redundancy.
- Temporal Similarity Reduction - Exploit the similarity between steps.
- Conditional Redundancy Elimination - Skips redundant computations during conditional generation.
Generation Speed Comparasion
Image Generation Results


Video Generation Results














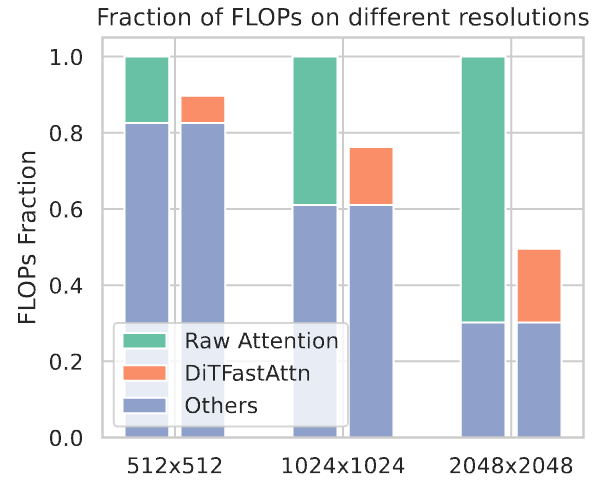
FLOPs Reduction
You can find the code for DiTFastAttn on GitHub at DiTFastAttention. Feel free to check out the repository for more details and to access the code.